
Le projet DBnomics a décidé de faire ce travail une fois pour toutes, pour vous! Ce billet décrit brièvement le projet et propose un bref mode d’emploi pour la recherche de données sur le site.
DBnomics récupère automatiquement les données mises librement à disposition sur les sites des principaux fournisseurs de données statistiques, nommés « providers » sur le site DBnomics. La plupart des sites sont visités tous les jours, de manière à assurer la mise à jour des données figurant sur le site.
Les données sont ensuite stockées selon un schéma commun qui inclut leurs caractéristiques (métadonnées) telles que communiquées par le fournisseur original. Elles sont accessibles directement sur le site web https://db.nomics.world ou automatiquement grâce à une interface de programmation (API).
Le projet veut ainsi contribuer au mouvement OpenData en facilitant l’accès aux données économiques publiques. Il entend également assurer un archivage permanent des données même lorsque celles-ci ont disparu du site de leur producteur original. Il conserve l’ensemble des révisions de données depuis le début de leur collecte, permettant, à terme, de comprendre comment la vision statistique d’un même fait économique varie au cours du temps. L’accès à l’histoire des révisions est en cours de développement.
DBnomics contient des données de 62 fournisseurs, soit environ 20 000 ensembles de données, appelés « datasets », et plus de 600 millions de séries chronologiques, appelées « series ». Elle rassemble des données des principales organisations internationales (Banque Mondiale, BIT, BRI, CNUCED, FAO, FMI, OCDE, OMC, ONU), d'agences régionales (AFDB, AMECO, BCE, EUROSTAT, BCEAO) et des données nationales en provenance de 24 pays répartis sur les cinq continents. Pour le Centre d'Etudes Prospectives et d'Informations Internationales (CEPII), DBnomics est le dépôt original des données sur les échanges internationaux et l’économie, CHELEM.
Etant donnée la nature internationale du projet, l'anglais a été choisi pour le site web et les métadonnées. Le projet DBnomics est soutenu par l’Agence française de développement, la Banque de France, le CEPREMAP et France Stratégie.
Recherche de données
Lorsqu’on sait chez quel fournisseur se trouvent les données que l’on cherche, le plus efficace est de parcourir l’arborescence du site. DBnomics s’efforce d’utiliser la même classification des ensembles de données que sur le site original.

Alternativement, il est possible de rechercher des données par mots-clés. Imaginons qu’on veuille trouver les émissions de CO² par grandes régions du monde, comme cela a été fait pour préparer les deuxième et troisièmes graphiques illustrant la première conférence des JECO 2019, “La transition c'est maintenant”. Sur la première page du site, on peut entrer le mot-clé “co2”, mais on veut aussi s’assurer qu’on obtienne des données sur la Chine, on ajoute donc “china”.
On obtient ainsi une liste de 11 ensembles de données chez différents fournisseurs. Pour une comparaison internationale, les World Development Indicators de la Banque Mondiale semblent une source prometteuse. Lorsqu’on clique sur le nom de l’ensemble de données, apparaît une sélection de 87 séries qui contiennent “co2”et “china” dans leurs métadonnées.
Le terme “co2” apparaît dans plusieurs concepts différents et le terme “china” renvoie non seulement à la République populaire de Chine, mais aussi à Hong Kong et à Macao.
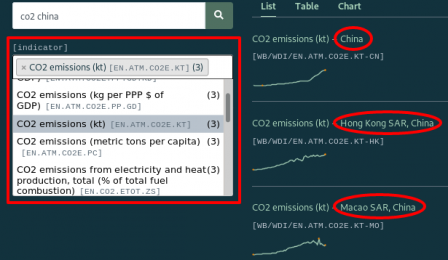
Parmi les différents indicateurs qui figurent sous “[indicator]” dans la colonne de gauche, nous choisissons CO2 emissions (kt) et sous “[country]” nous choisissons China. Il ne reste plus qu’une seule série sélectionnée : CO2 emissions (kt) – China.
Les données de la série chronologique apparaissent en cliquant sur “Table”, au haut de la colonne de droite. Un graphique est affiché en cliquant sur “Chart”. Le lien “List” ramène l’utilisateur à la liste des séries.
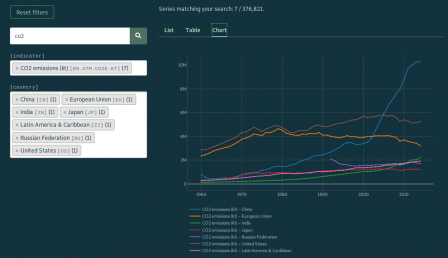
Notre but initial était de trouver des données non seulement pour la Chine, mais pour plusieurs régions du monde. En haut la colonne de gauche, on retire “china” des termes de recherche, ne laissant que “co2”, puis on clique sur la loupe à droite pour rafraîchir la sélection. Sous “[country]”, on peut maintenant choisir d’autres régions. En plus de China, on choisit European Union, India, Japan, Latin America & Caribbean, Russian Federation, United States. Il y a maintenant sept séries sélectionnées. En cliquant sur “Chart”, les sept séries figurent sur le même graphique, similaire à celui utilisé pour illustrer la conférence mentionnée ci-dessus.
Les données sélectionnées peuvent être téléchargées en cliquant sur le bouton “Download”, en haut de la page à droite. Les formats disponibles sont un fichier Excel ou fichier texte (CSV). Le lien API peut être utilisé pour récupérer les données sélectionnées, en format JSON, par un autre logiciel.
Lorsqu’on connaît le fournisseur des données que l’on cherche, il est souvent plus efficace de parcourir la classification des ensembles de données. Par exemple, cherchons des données trimestrielles de comptabilité nationale sur la consommation finale des ménages sur Eurostat. Sur la première page d’Eurostat, on ouvre « Databases by themes ». On clique sur « Economy and Finance », puis « National Accounts (ESA 2010) », puis « Quarterly National Accounts », puis « Main GDP aggregates ». Les données que l’on cherche se trouve sans doute dans l’ensemble de données « Final consumption aggregates ». Le système de classification des ensembles de données est, dans la mesure du possible, identique à celui utilisé sur le site Web du fournisseur original.

L’ensemble de données « Final consumption aggregates » contient 4 740 séries chronologiques. Il convient de préciser la recherche en utilisant les facettes comme dans l’exemple précédent. On doit alors choisir le concept, « National accounts indicator », le ou les pays, « Geographical entity », l’unité de mesure, « Unit of measure » et le type d’ajustement pour la saisonnalité, « Seasonal adjustment ».
Téléchargement automatique de données
L’application DBnomics est centrée sur la collecte et la mise à disposition des données. Elle fournit des outils d’aide à la recherche de données, mais elle ne contient pas d’outils avancés pour le traitement des données. L’interface graphique est proposée pour aider au processus de découverte et de sélection des données, elle n’est pas conçue pour fournir des graphiques prêts à être publiés. Pour les usages avancés, il vaut mieux télécharger les données et les traiter avec un logiciel approprié. Par exemple, les graphiques illustrant la conférence, “La transition c'est maintenant”, ont été réalisés à l’aide du logiciel R. Le code R est disponible ici. On peut remarquer que quelques lignes seulement sont nécessaires pour acquérir les données alors que l’essentiel du code est consacré à la préparation des graphiques.
Il existe des clients pour R, Python, Stata et Julia qui permettent de télécharger des données DBnomics directement depuis ces logiciels. Ces outils peuvent grandement faciliter les tâches récurrentes telles que la mise à jour régulière de tableaux de bord, de rapports ou de la base de données d’un modèle. Utiliser un programme plutôt qu’une opération manuelle explicite ce qui a été fait et permet de répéter l’opération à l’identique dans le futur. Ces clients exploitent l’API de DBnomics qui est documenté à https://api.db.nomics.world/v22/apidocs.
Michel Juillard interviendra sur la conférence : L'enseignement de l’économie en licence et au lycée
Pour aller plus loin
DBnomics est un projet vivant. De nouveaux fournisseurs et ensembles de données seront ajoutés prochainement. Vous pouvez y contribuer en posant des questions, en rapportant les erreurs ou en suggérant des améliorations ou des nouvelles fonctionnalités sur le forum (https://forum.db.nomics.world/). Des développeurs en Python peuvent concevoir le code nécessaire à acquérir les données de nouveaux fournisseurs.
Liens utiles
• Site du projet : https://db.nomics.world/
• API : https://api.db.nomics.world/v22/apidocs
• Forum : https://forum.db.nomics.world/
• Tickets : https://git.nomics.world/dbnomics-fetchers/management/issues
• Client R : https://git.nomics.world/dbnomics/rdbnomics
• Thomas Brand (2019) « Access the free economic database DBnomics with R » https://macro.cepremap.fr/article/2019-10/rdbnomics-tutorial/
• Client Python : https://git.nomics.world/dbnomics/dbnomics-python-client
• Client Julia : https://github.com/s915/DBnomics.jl
• Client Stata : https://github.com/dreameater89/dbnomics
• Code DBnomics : https://git.nomics.world/dbnomics
• Fetchers : https://git.nomics.world/dbnomics-fetchers
• Wiki des développeurs : https://git.nomics.world/dbnomics-fetchers/documentation/wikis/home